Recommend System Lecture Note(4)
July 2021 (676 Words, 4 Minutes)
이번 시간의 key word는 다음과 같다.
- Latent Dirichlet Allocation
- Embedding & Word2Vec
- Item2Vec
- Multi-Armed Bandit
(자연어처리에서 들어본 임베딩, Word2Vec을 제외한 나머지는 전혀 처음 들어보는 생소한 단어였다..)
4-1. Latent Dirichlet Allocation을 이용한 추천
Latent Drichlet Allocation( LDA )는 토픽 모델링 중 하나의 알고리즘이다. 토픽 모델링이란 문서들의 집합에서 토픽을 추출하는 프로세스를 의미한다. 일종의 카테고리를 지칭하는 것 같다. LDA는 주어진 문서와 각 문서가 어떤 토픽을 가지는지 확률 모형으로 풀어낸 과정이다. 나는 문서의 레이블이라 이해하고 어떤 주제를 포함하는지 분류하는 과정으로 이해하였다.
각 토픽의 단어 분포, 각 문서의 토픽 분포를 Dirichlet 분포로 가정하고 추정한다고 한다. 토픽을 단어들의 분포로 정의하고 어떤 문서에서 단어들이 분포했을 때 각 단어가 갖고 있는 토픽을 분석하는 과정에서 기반이 되는 개념이다.
예를 들어, 아래와 같은 문서가 있다
doc1: 나는 추천을 공부한다.
doc2: 나는 영화 아이언맨을 봤다.
doc3: 추천을 통해 영화를 봤다.
문서의 토픽 분포 를 표현하면
doc1: topicA(100%)
doc2: topicB(100%)
doc3: topicA(60%), topicB(40%)
라고 할 때 각 토픽의 단어 분포 를 살피면
- topic A
| 나는 | 추천을 | 공부한다 | 영화를 | 아이언맨을 | 봤다 | 통해 |
|---|---|---|---|---|---|---|
| 10% | 40% | 25% | 5% | 5% | 10% | 5% |
- topic B :
| 나는 | 추천을 | 공부한다 | 영화를 | 아이언맨을 | 봤다 | 통해 |
|---|---|---|---|---|---|---|
| 10% | 10% | 5% | 25% | 30% | 15% | 5% |
LDA는
- 문서의 생성이 토픽(들)을 고르고,
- 선택된 토픽의 확률 분포로부터 단어 하나를 골라
- 문서에 넣는 과정을 N번 반복하여 N개의 단어를 구성한다 는 과정을 기반으로 한다. 위의 예시에서 토픽으로 A를 골랐다면, topic A의 단어 분포에 따라 단어를 선택하여 문서를 작성하게 된다.
LDA를 학습하게 되면
- 문서의 토픽 분포 : 토픽 갯수 k차원의 벡터( 전체 합 = 1 )
- 토픽의 단어 분포 : 단어 갯수 N차원의 벡터( 전체 합 = 1 )
를 구할 수 있다.
토픽 갯수 최적화
위에서 토픽 갯수 k는 파라미터의 하나로 최적의 토픽 갯수를 구하는데 Perplexity 지표를 활용한다.
이는 예측 결과에 대한 평가 지표로 문서 내 각 단어의 발생확률(p(w))이 클수록 잘 학습되었다고 할 수 있다.

Perplexity가 작은( p(w) 단어의 발생확률이 커질수록 Perplexity는 작아짐 ) 토픽 수 k를 최적의 토픽수로 설정한다.
LDA를 이용한 추천
그렇다면, LDA를 추천에 어떻게 적용할 수 있을까?
유저(문서)는 토픽 분포를 갖게 되고 각 토픽별로 아이템(단어) 분포를 갖게 된다.
즉, 유저가 어떤 토픽에 관심이 높다면 해당 토픽의 발생확률이 높은 아이템을 추천해주면 된다.
k개의 토픽에 대해 유저 & 아이템 스코어를 구한 뒤 가장 높은 score를 가지는 아이템을 추천한다. score는 (유저에 할당된 확률 * 토픽의 아이템 발생 확률) 에 따라 계산한다.
예를 들어,
유저의 토픽 분포 : A(0.2) / B(0.8)
토픽의 단어 분포 : A(0.4, 0.2, 0.4) / B(0.7, 0.1, 0.2)
이면 유저와 첫번째 아이템의 score = 0.2 * 0.4 + 0.8 * 0.7 = 0.64로 계산된다.
4-2. Embedding & Word2Vec
Embedding
임베딩이란
고차원 벡터의 변환을 통해 생성할 수 있는 상대적인 저차원 공간
을 의미한다.
벡터를 표현하는 방법은 일단 아래 2가지가 있다.
Sparse Representation
주로 one-hot encoding 또는 multi-hot encoding으로 표현된다. 이전의 유저-아이템 sparse matrix도 이 방식으로 표현되었고 벡터 차원은 아이템 전체 갯수와 같다. 따라서 벡터의 차원이 한없이 커질 수 있다는 단점이 있다.
Dense Representation
아이템 전체 갯수보다 훨씬 작은 차원으로 표현되고, binary가 아닌 실수값으로 벡터를 구성한다.
Word2Vec
워드 임베딩은 정해진 사이즈의 dense vector로 나타낸다. 비슷한 의미의 단어끼리는 벡터의 비슷한 위치에 분포하여 단어간 유사도를 구할 수 있다. 이전의 Matrix Factorization도 유저-아이템의 임베딩이라 할 수 있다.
워드 임베딩의 방법론 중 하나인 Word2Vec은 뉴럴 네트워크 기반이다. 대량의 문서 데이터를 벡터 공간에 투영하여 dense vector로 표현한다. 빠른 학습이 가능하다는 특징이 있다.
학습 방법에는 크게 CBOW, Skip-gram이 있다.
CBOW( Continuous Bag of Words )
주변에 있는 단어로 센터에 있는 단어를 예측하는 방법. 단어를 예측하는데 앞뒤로 몇 개의 단어를 참고할 것인지 설정하는데 window = N이라면 하나의 단어에 대해 2N개의 단어가 사용된다.
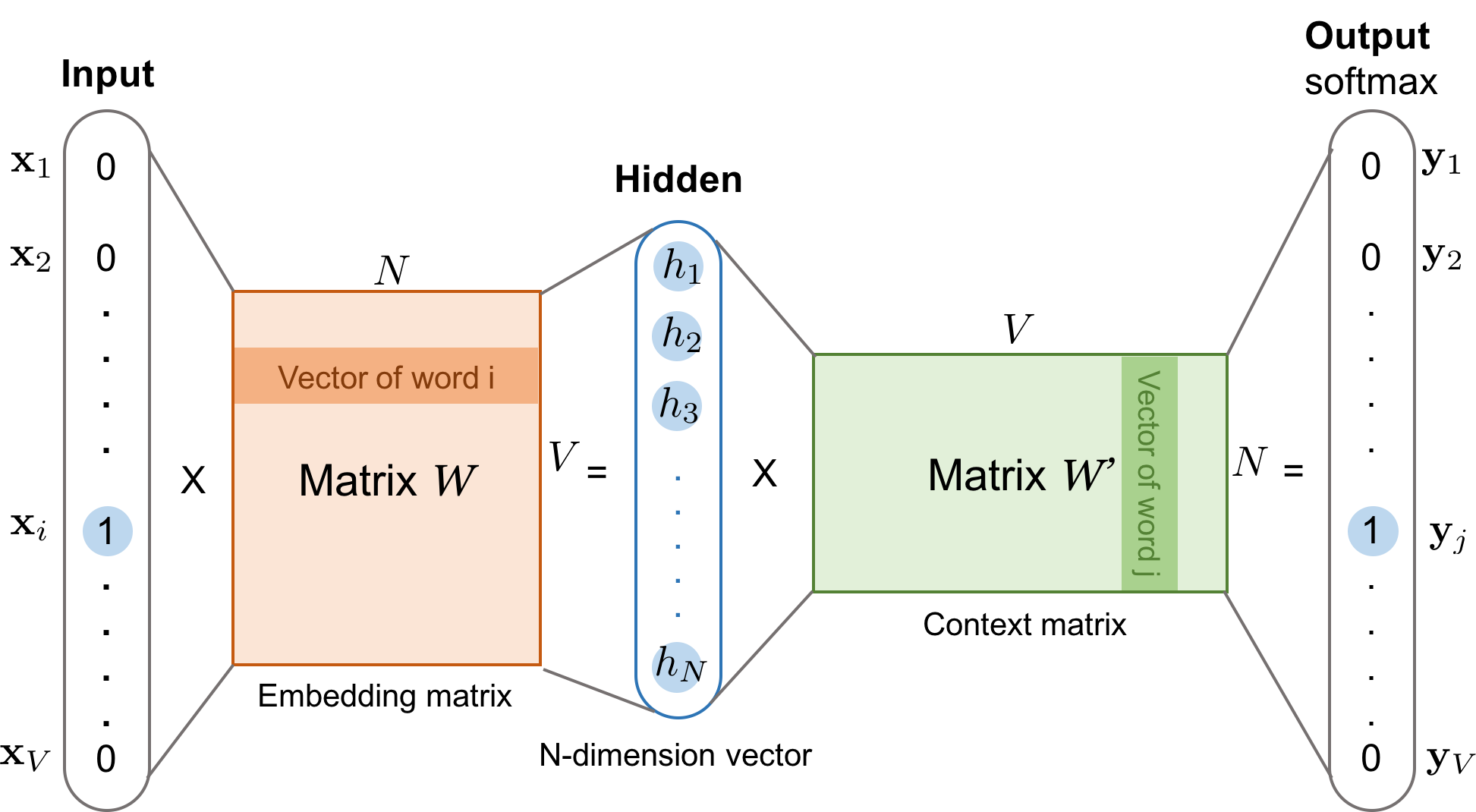
마지막 output layer에서 softmax 를 적용해서 전체 합 = 1이 되도록 한다. 여기서 가장 높은 확률을 가지는 class가 예측 단어가 된다.
Skip-gram
CBOW의 입력층과 출력층이 반대로 구성된 모델.

Skip-gram Negative Sampling(SGNS)은 예외 샘플(Negative)을 포함하여 학습에 이용한다.


중심단어(입력1), 주변단어(입력2)는 서로 다른 임베딩 벡터를 가진다.

- 중심 단어를 기준으로 주변 단어들간 내적곱( float )에 sigmoid를 적용해 0 또는 1로 분류한다.
- Backpropagation으로 각각의 임베딩이 업데이트된다.
- 최종 임베딩 벡터는 2개이므로 하나만 사용하거나 평균으로 사용한다.

Item2Vec
위의 경우처럼 단어를 아이템으로 가정하여 추천 아이템을 Word2Vec에 적용한다.
- 유저 / 세션별 소비한 아이템 집합을 생성
- 동일한 아이템 집합 내의 아이템은 SGNS Word2Vec의 Positive Sample
- 아이템 벡터 간 유사도는 코사인 유사도를 사용함
4-3. Multi-Armed Bandit( WIP )
강화학습의 핵심 아이디어인 Exploitation과 Exploration을 활용한 알고리즘이다.
Multi-Armed Bandit의 핵심은 K개의 슬롯머신을 총 n번 플레이할 수 있을 때 수익을 최대화하기 위해 arm을 어떤 policy에 따라 당겨야 하는지에서 나왔다. 각각의 슬롯머신의 reward는 모두 다르고 reward는 0 또는 1이라고 가정한다. 여기서, Exploration은 더 많은 정보를 위해 새로운 arm을 선택하는 것이고, Exploitation은 기존의 경험이나 관측값을 토대로 가장 좋은 arm을 선택하는 것이다.
Exploration이 너무 적으면 reward가 낮은 슬롯머신에 Exploitation할 수 있고, 반대로 너무 많으면 비용이 커져 높은 reward를 보장할 수 없다.

※ 강의노트는 러닝 스푼즈의 추천시스템 구현하기 수업을 듣고 정리한 내용이다.