home..
Airflow documentation - Mechanism
November 2021 (575 Words, 4 Minutes)
airflow는 자동으로 스케줄링하고 모니터링하기 위한 플랫폼이다. 워크플로우를 DAG구조( Directed Acyclic Graphs )로 파악할 수 있다.
다음과 같은 특징이 있다.
- dynamic : airflow 파이프라인은 파이썬 코드로 작성한 configuration이다. 동적으로 코드를 수정 가능하다.
- extensible : operator를 정의하기 쉽다.
- elegant : Jinja를 활용한 scripts로 명확한 airflow 파이프라인을 만들 수 있다.
- scalable : module과 message queue를 이용하여 임의의 workers를 운영할 수 있다.
동작 원리
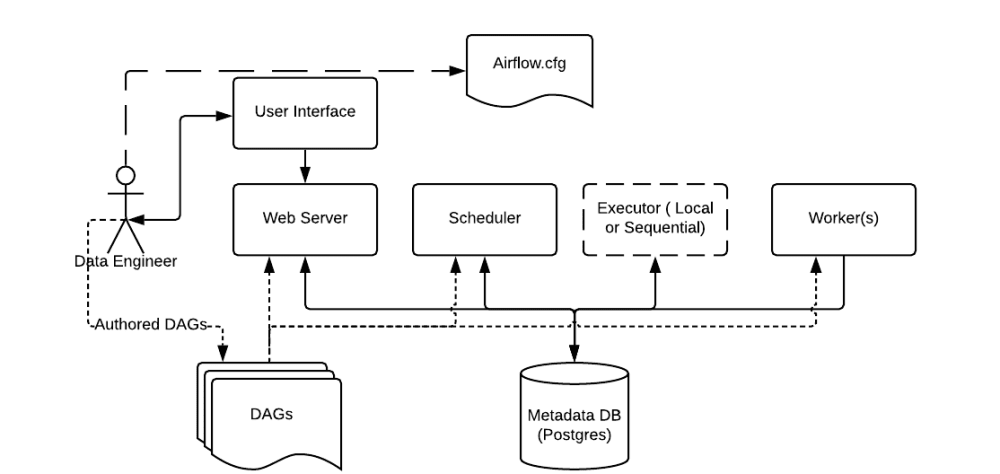
- Scheduler : 모든 DAG와 Task에 대하여 모니터링 및 관리하고, 실행해야할 Task를 스케줄링한다.
- Web server : Airflow의 웹 UI 서버
- DAG : Directed Acyclic Graph로 개발자가 Python으로 작성한 워크플로우
- Database : Airflow에 존재하는 DAG와 Task들의 메타데이터를 저장하는 데이터베이스이다. 어떤 DAG가 존재하고 어떤 Task로 구성되었는지, 어떤 Task가 실행 중이며 실행 가능한지 정보가 저장된다.
- Executor : Task 인스턴스를 실행하는 주체
- Worker : 실제 Task를 실행하는 주체이며 Executor의 종류에 따라 상이하다.
[ 예시 ]

- HiveOperater로 실행할 쿼리를 입력하여 Task를 실행하면 내부적으로 Hive CLI를 생성한다.
-
스케줄러는 Airflow 워커를 생성한다.
LocalWorker에서 프로세스 형태로 워커가 실행된다. 아래command는 워커를 실행시키는 명령어로 보면 된다.class LocalWorker(multiprocessing.Process, LoggingMixin) ... def execute_work(self, key, command): if key is None: return self.log.info("%s running %s", self.__class__.__name__, command) try: subprocess.check_call(command, close_fds=True) state = State.SUCCESS except subprocess.CalledProcessError as e: state = State.FAILED self.log.error("Failed to execute task %s.", str(e)) self.result_queue.put((key, state)) - HiveOperater로 통해 만들어진 Hive 명령어가 실행되고 Hive Java 프로세스가 수행된다.
Executor
Executor는 task 인스턴스를 실행하는 주체이다. Sequential Executor, Local Executor, Celery Executor, Dask Executor, Kubernetes Executor를 제공한다.
Local Executor
단일 장비에 웹 서버와 스케줄러를 같이 가동하고 task를 프로세스로 spawn하여 실행한다. Local Executor는 parallelism에 따라 나뉘는데 task_queue를 통해 실행한 task 수에 대해 제어한다.
parallelis이 0이 아니면 설정 수만큼 task 수를 제한한다.
class LocalExecutor(BaseExecutor)
...
def start(self):
self.manager = multiprocessing.Manager()
self.result_queue = self.manager.Queue()
self.workers = []
self.workers_used = 0
self.workers_active = 0
self.impl = (LocalExecutor._UnlimitedParallelism(self) if self.parallelism == 0
else LocalExecutor._LimitedParallelism(self))
self.impl.start()
class _UnlimitedParallelism(object)
...
def start(self):
self.executor.workers_used = 0
self.executor.workers_active = 0
def execute_async(self, key, command):
local_worker = LocalWorker(self.executor.result_queue) # result_queue를 대상으로 local를 생성한다.
local_worker.key = key
local_worker.command = command
self.executor.workers_used += 1
self.executor.workers_active += 1
local_worker.start()
class _LimitedParallelism(object)
...
def start(self):
self.queue = self.executor.manager.Queue() # result_queue, task_queue를 대상으로 local 워커 수를 제한한다.
self.executor.workers = [
QueuedLocalWorker(self.queue, self.executor.result_queue)
for _ in range(self.executor.parallelism)
]
self.executor.workers_used = len(self.executor.workers)
for w in self.executor.workers:
w.start()
def execute_async(self, key, command):
self.queue.put((key, command))
[출처] https://engineering.linecorp.com/ko/blog/data-engineering-with-airflow-k8s-1/?fbclid=IwAR1g_gWEmZ9hdPvICeXfZI2pI2yHhvH4vMHO1Jl5VI2EeS-kk5Q55_BcFdQ [참고]
- schedule 시간에 대한 이해 : https://blog.bsk.im/2021/03/21/apache-airflow-aip-39/